Bazaar Ghost
On November 2nd, I released https://www.bazaarghost.stream into the wild. The next day, I made a post on the Bazaar subreddit that went fairly viral, at least in terms of the relative size of the community
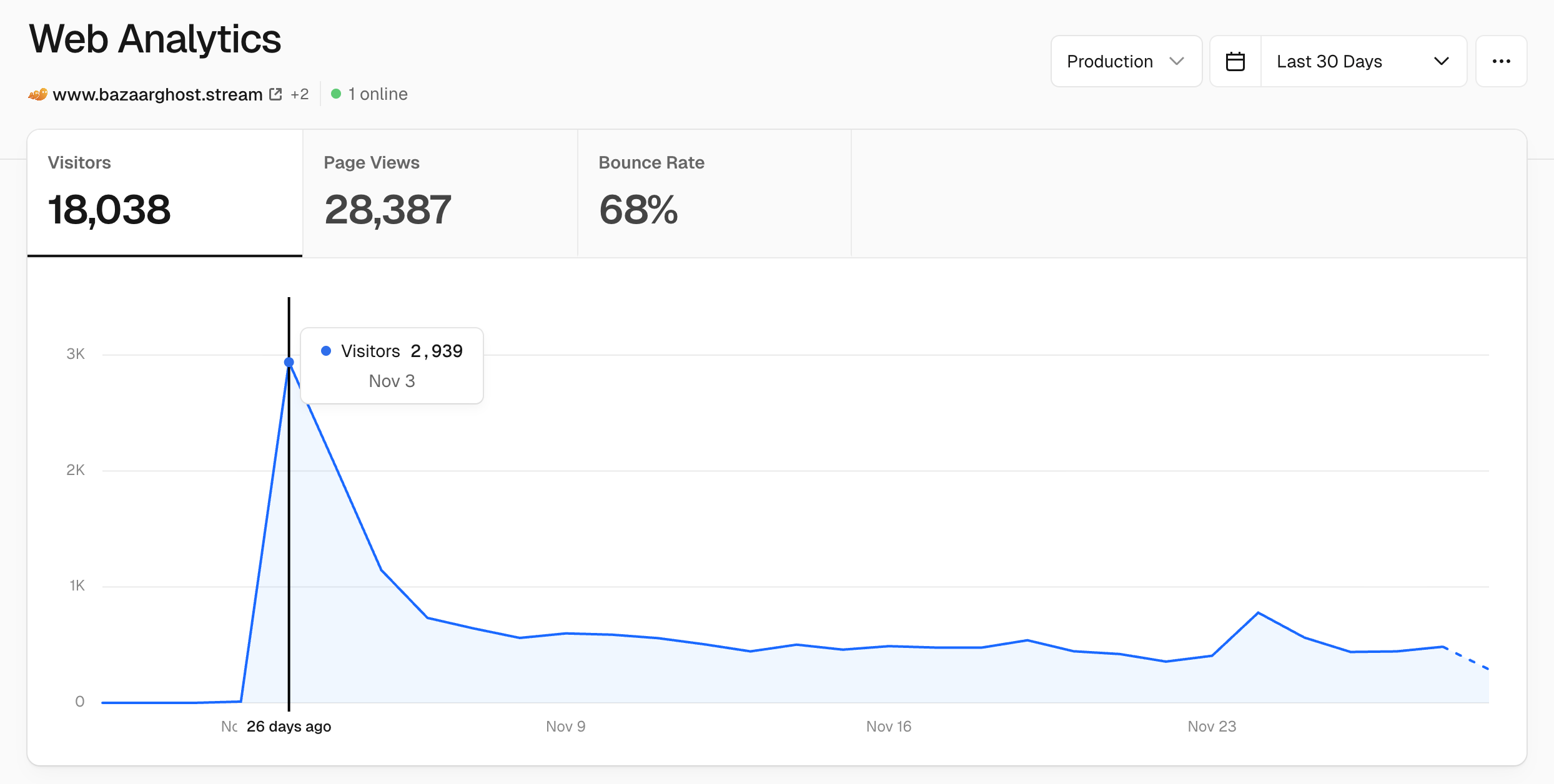
Today is November 29th, approaching one month since release, and so far BazaarGhost has seen ~18,000 visitors (with a non-peak average of ~550 visitors per day). Today I'm writing about my experience building the site, reflecting on the experience, and putting down my thoughts about it moving forward.
What is it?
BazaarGhost.Stream is a site that lets you look up matches between streamers and past versions of players' boards, aka ghosts.
About The Bazaar
If you know about The Bazaar you can skip this section. Otherwise, read on because the site's purpose is not intuitive unless you're familiar with the game.
Here's the basic description of the game:
- The Bazaar is an auto-battler with asynchronous PvP
- You get matched up against other players, but not in realtime
- Combines card game mechanics with the auto-battler genre established by games like Riot Game's Teamfight Tactics, or the OG Dota Auto Chess
- Gamplay loop: An in-game "day" is comprised of six "hours", where each hour you make decisions between spending gold to buy items, fighting monsters, or other random events leading up to hour six, where you fight the ghost of another player—a snapshot of what their board looked like on the same day.
- You start with 20 prestige. When you're defeated by another player you lose prestige equal to the day you are on.
- Win as many days as you can (up to 10) before running out of prestige.
Because of The Bazaar's asynchronous nature, a ghost version of your board continues on even after you're done playing, and this is where BazaarGhost comes in
The problem BazaarGhost solves
At the moment, there is no in-game way to see how your ghost does against other players from their perspective. A lot of the fun of your game is optimizing your board against unpredictable enemies. Any board you put together, no matter how good, can generally be defeated by something even more powerful for a given matchup. BazaarGhost gives you the satisfaction of seeing your or your friends' ghost go up against streamers of the game on Twitch, along with their reactions to the strength (or weakness!) of the build you managed to cobble together.
How It Works
Though I have a page about this on the site, in this blog post I want to go into a bit more technical detail.
- Find and catalog archived streams (VODs) on Twitch that contain at least some gameplay of The Bazaar
- Process each stream with:
- Streamlink: cli tool to get Twitch
.hlsstreams and pipe it into… - Ffmpeg: filters and crops incoming frames to the region of interest, keeping a record of the timestamp associated with each frame.
- OpenCV: use
matchTemplateto determine whether current frame is a matchup screen or not, based on a given template image. - Tesseract: Optical Character Recognition (OCR) engine for extracting text from images.
- Save the results to the Postrgres database hosted on Supabase
- A very lightweight Next.js frontend that searches and surfaces results of username queries, with links to the VOD where the matchup occurred
Whoa the bold letters in that one bullet list spells out SFOT, I wonder if that's the lazy shorthand I use to refer to the stream processing step. Yeah, simply put it's a container that takes in a vod id as input and orchestrates S, F, O, and T to spit out usernames with timestamps of where they appear in the VOD.
How it Started
The first version of BazaarGhost actually started earlier this year, around March 2025. Among the playerbase, I was far from the only one who had the thought of seeing how my ghosts performed vs others.
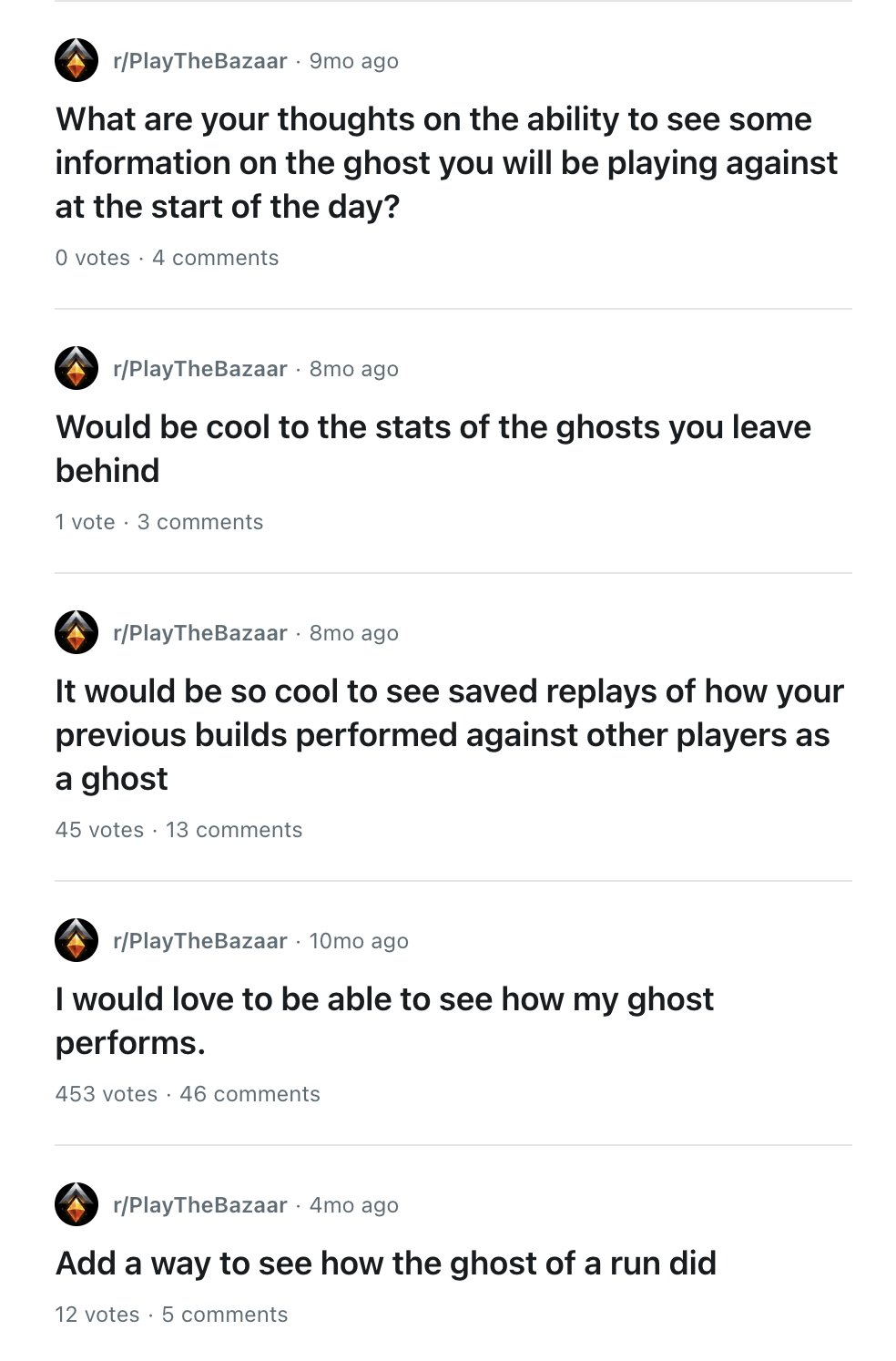
A search for "see your ghost" in r/PlayTheBazaar over the last 12 months shows the demand for a feature to see how your ghost performs against other players
I started with some AI slop-scripts to check if I had any matchups against Kripp, the largest streamer of The Bazaar. The prototype was a contrived piece of "works on my machine" ethos, but after seeing it kind of working and letting the concept brew over six months of no-progress while on an intense project at my day job, I got back to work on it towards the end of September/early August.
This is going to be expensive—unless…?
Yeah, the proof of concept worked, but I was running the SFOT container on my machine. I could just update the database once a day, that wasn't the level of "scalable" I wanted. Plus, back-filling thousands of old VODs would've meant letting my PC churn for days, which sounded miserable. The alternative was cloud jobs, I immediately started weighing my options.
- Cloud hosted Virtual Private Server (VPS) — Services like Hetzner, DigitalOcean, Oracle… a cheap one could be $5 a month, but for what I could get at that price, I was not sure I could process more than once VOD at a time
- Serverless — the buzzword of the decade. There was a bit where I felt like I had 12 different
/pricingtabs from all sorts of services: Google Cloud Jobs, AWS Lambdas, Render, Fly.io, the list goes on. Between trying to calculate my predicted usage, looking for promo and credit offers or differing free trial lengths, I feel like I was on a cheapskate version of hero's journey, trying to outsmart the "creative" pricing strategies of the serverless landscape. Eventually my stubborn frugality paid off when I found…
The Answer.
Github Actions (GHA). As it turns out, you can run babies all day long as long as you're repo is public and you're not abusing their infrastructure. Since BazaarGhost is neither a product I'm trying to sell nor a state secret, I had no problem building it in the open, and making the best out of the generous—and most importantly—free, github actions.
Putting it together
With the weight of cost removed, I was giddy to know that my project was feasible at (a relatively small) scale, at little to no cost.

Supabase
Supabase is doing a lot of heavy lifting here. I use Supabase Edge Functions to handle the discovery side:
insert-new-streamerspolls the Twitch API for recent Bazaar VODs and adds any new streamers to the databaseupdate-vodsfetches the VOD catalog for each streamer, filtering only for VODs that have Bazaar gameplay chapters
The PostgreSQL database tracks everything: streamers, vods, chunks, and detections. A VOD can be hours long, so I split each one into chunks for processing. This is tracked in the chunks table, which stores the start/end timestamps and processing status for each segment. When processing completes, the extracted usernames and timestamps land in detections.
Supabase Storage holds the frame images for each detection. These actually aren't relevant to the end user, I kept them for debugging purposes. If a username was badly extracted, I could reference the image it rand OCR on to see if there was a mistake with emblem detection, OCR settings, or something else.
Cron jobs handle the scheduling: periodically calling the edge functions to discover new VODs and kicking off the process-vod GitHub workflow for any VODs that need processing.
The process-vod workflow is the bridge between Supabase (control plane) and GitHub Actions (data plane). When a cron job identifies a VOD ready for processing, it triggers process-vod.yml via the GitHub API. The workflow first checks if the VOD is still available on Twitch and determines the best quality to use (preferring 480p to balance processing speed and detection accuracy). It then fetches all pending chunks for that VOD from Supabase and spins up parallel jobs to process them.
SFOT: The Data Plane
The SFOT container is where the actual frame processing happens. It's a Docker image that gets built fresh in each GitHub Actions run (with layer caching to speed things up). The same container runs locally for development.
Here's what the workflow looks like in practice:
process-vod.yml triggered for VOD 2345678901
│
├─► check-vod job
│ └─► Verify VOD available, select quality (480p)
│
├─► fetch-chunks job
│ └─► Query Supabase for pending chunks → [chunk1, chunk2, ...]
│
└─► process-chunk jobs (matrix strategy, up to 20 parallel)
├─► chunk1 → SFOT container → detections
├─► chunk2 → SFOT container → detections
├─► chunk3 → SFOT container → detections
│ ...
└─► chunkN → SFOT container → detectionsEach chunk job builds the SFOT container, then runs it with environment variables pointing to Supabase and the specific chunk ID. The container handles everything from there: fetching chunk details, streaming the VOD segment, extracting frames, detecting matchup screens, running OCR, and uploading results back to Supabase. Failed chunks can be retried independently without reprocessing the entire VOD.
Frontend
The frontend is intentionally minimal. It's a quick Next.js on Vercel, a search box, and results that link directly to the timestamp in the VOD. I also disabled image optimization, because those use up a ton of Vercel edge function invocations. On the free/hobby tier, it's quite easy to hit the limit. As a consequence, images don't load as fast but since it's not a big part of the UX. Most of the images are the streamer avatars that show up in the search results.
Final Thoughts
BazaarGhost started as a curiosity, and it is now a great source of fulfillment outside of work, something I was previosuly lacking. It has been so rewarding to see all the dicussion surrounding it, and to see people have positive experiences with the site, even if small.
Thanks for reading, and if you haven't already, go check if your ghost has been spotted at bazaarghost.stream.